Scalability
Scalability
As a system grows, the performance starts to degrade unless we adapt it to deal with that growth.
Scalability is the property of a system to handle a growing amount of load by adding resources to the system.
How can a System Grow?
A system can grow in several dimensions.

1. Growth in User Base
More users started using the system, leading to increased number of requests.
Example: A social media platform experiencing a surge in new users.
2. Growth in Features
More features were introduced to expand the system's capabilities.
Example: An e-commerce website adding support for a new payment method.
3. Growth in Data Volume
Growth in the amount of data the system stores and manages due to user activity or logging.
Example: A video streaming platform like youtube storing more video content over time.
4. Growth in Complexity
The system's architecture evolves to accommodate new features, scale, or integrations, resulting in additional components and dependencies.
Example: A system that started as a simple application is broken into smaller, independent systems.
5. Growth in Geographic Reach
The system is expanded to serve users in new regions or countries.
Example: An e-commerce company launching websites and distribution in new international markets.
How to Scale a System?
Here are 10 common ways to make a system scalable
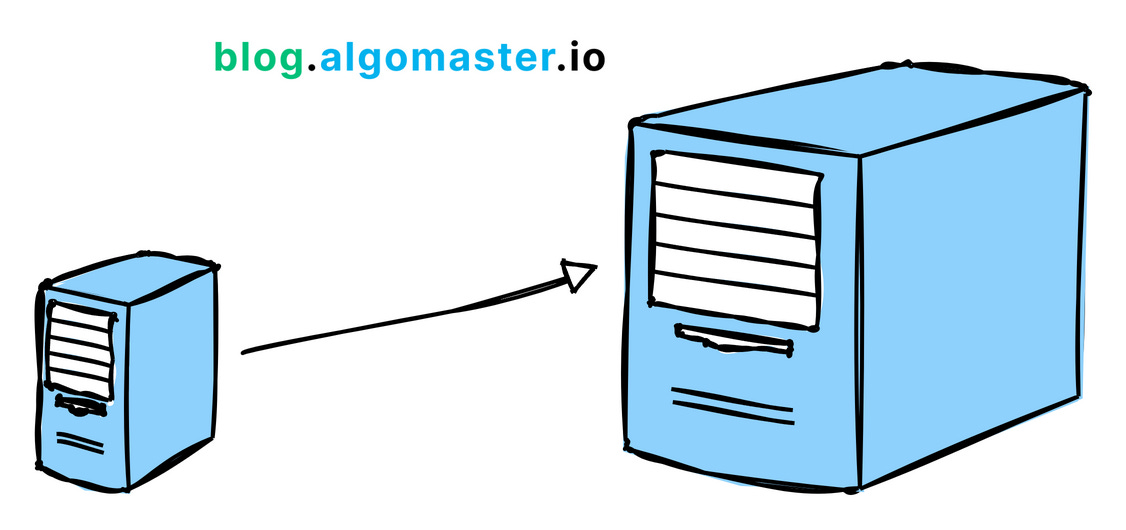
1. Vertical Scaling (Scale up)

This means adding more power to your existing machines by upgrading server with more RAM, faster CPUs, or additional storage. It's a good approach for simpler architectures but has limitations in how far you can go.
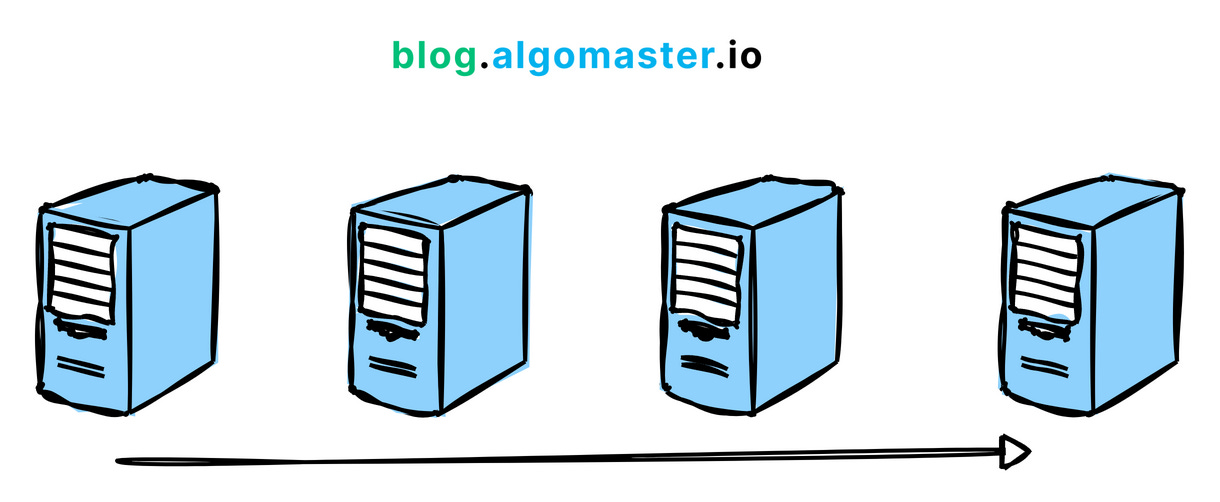
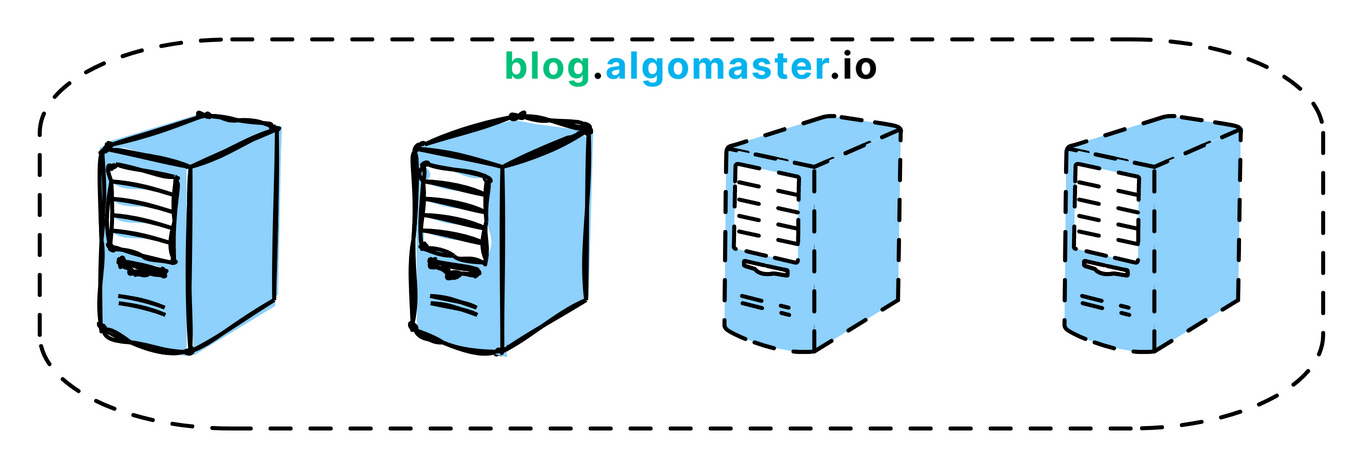
2. Horizontal Scaling (Scale out)

This means adding more machines to your system to spread the workload across multiple servers. It's often considered the most effective way to scale for large systems.
Example: Netflix uses horizontal scaling for its streaming service, adding more servers to their clusters to handle the growing number of users and data traffic.
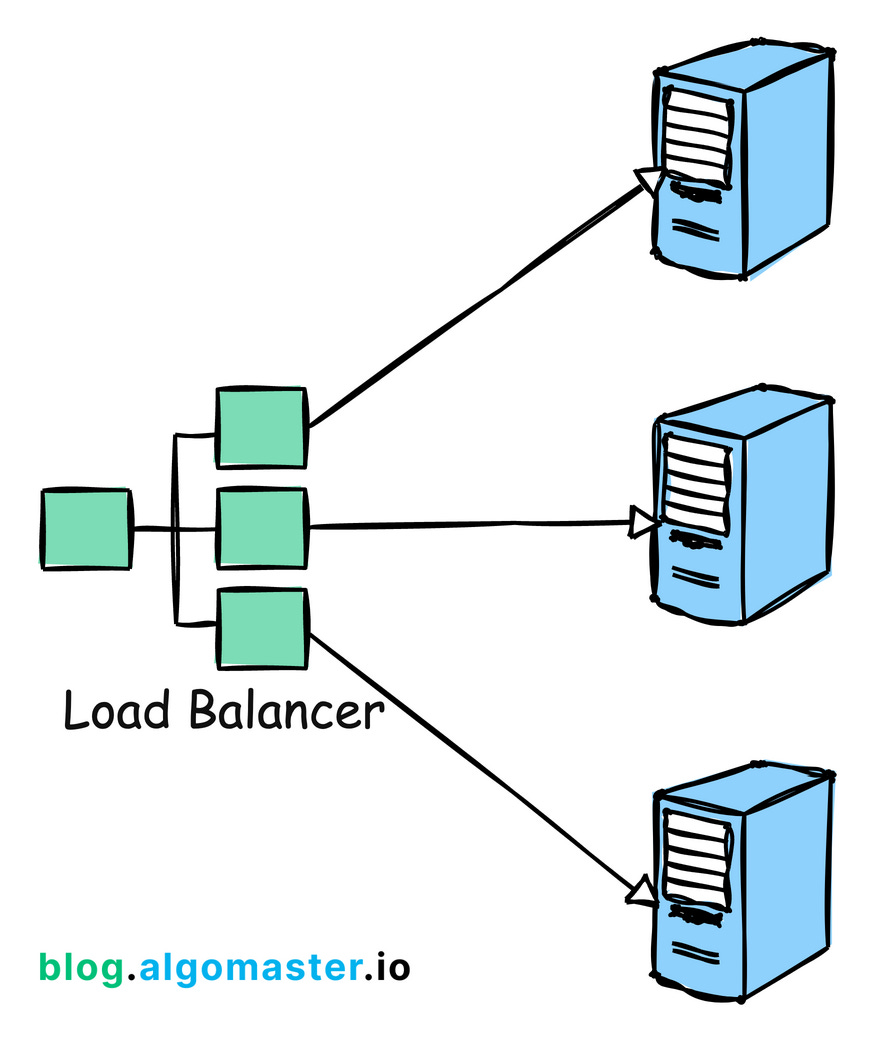
3. Load Balancing

Load balancing is the process of distributing traffic across multiple servers to ensure no single server becomes overwhelmed.
Example: Google employs load balancing extensively across its global infrastructure to distribute search queries and traffic evenly across its massive server farms.
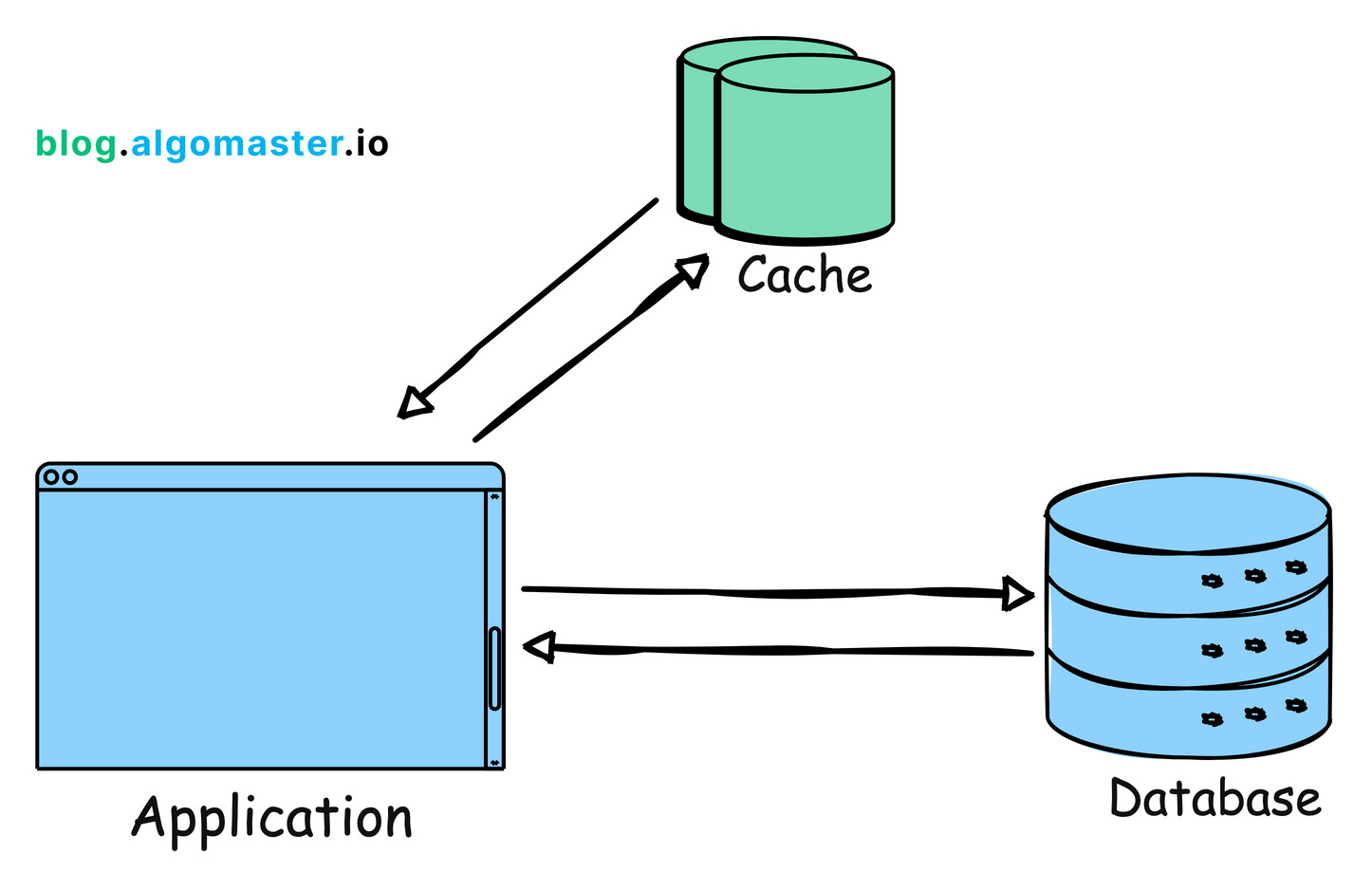
4. Caching

Store frequently accessed data in-memory (like RAM) to reduce the load on the server or database. Implement caching can dramatically improve response times.
Example: Reddit uses caching to store frequently accessed content like hot posts and comments so that they can be served quickly without querying the database each time.
5. Content Delivery Networks (CDNs)

Distribute static assets (images, videos, etc.) closer to users. This can reduce latency and result in faster load times.
Example: Cloudflare provides CDN services, speeding up website access
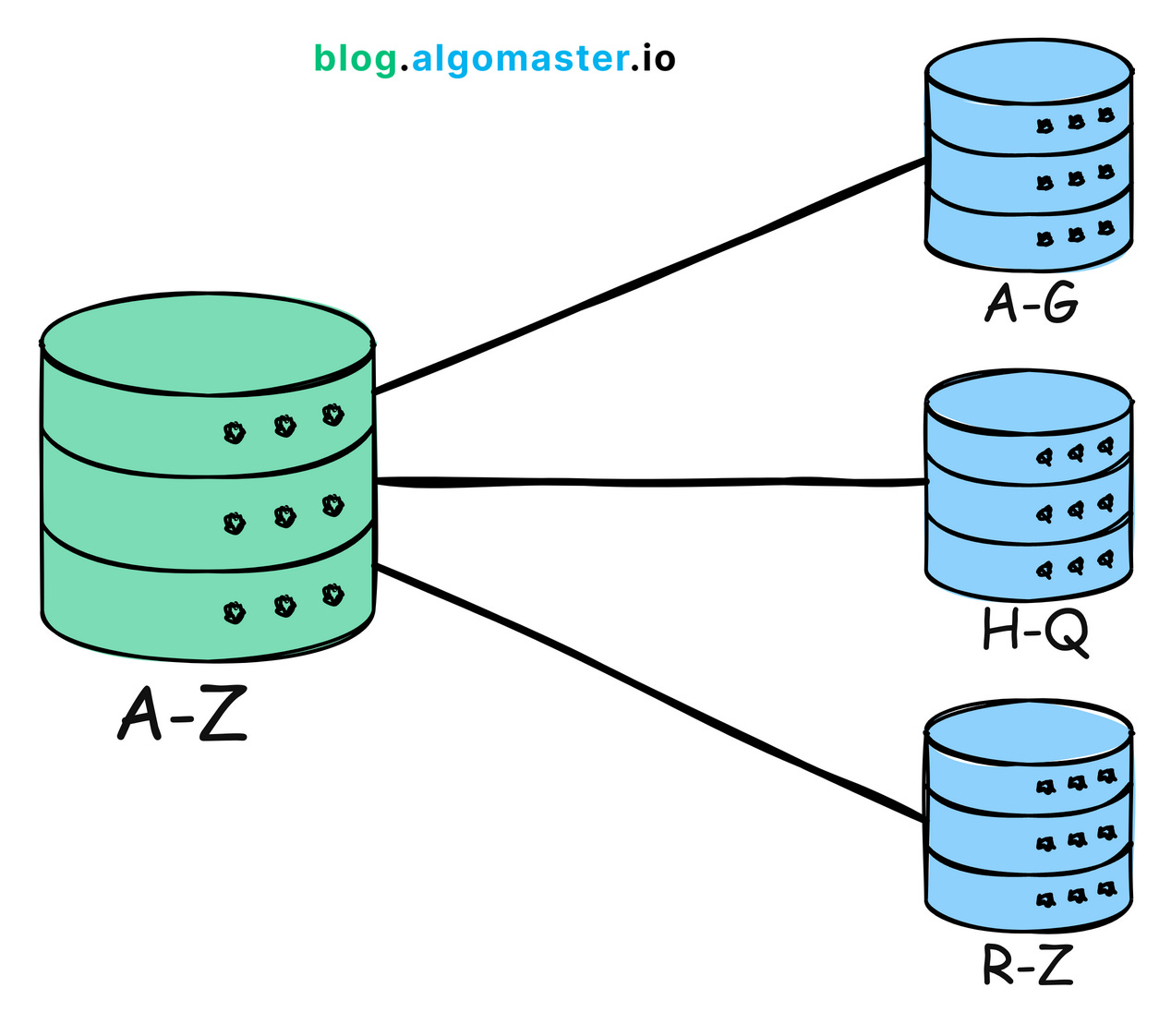
6. Sharding
As your system’s data grows, managing and accessing it efficiently can become a challenge. Sharding is a technique that involves splitting your data into smaller, more manageable partitions (or shards) and distributing them across multiple servers. This approach can help reduce the load on individual nodes, improve query performance, and enable horizontal scaling. However, sharding comes with its own set of complexities, such as handling cross-shard queries and ensuring data consistency, so it’s essential to carefully plan and implement a sharding strategy that suits your system’s requirements

Example: Amazon DynamoDB uses partitioning to distribute data and traffic for its NoSQL database service across many servers, ensuring fast performance and scalability.
7. Asynchronous communication
Defer long-running or non-critical tasks to background queues or message brokers. This ensures your main application remains responsive to users.
Example: Slack uses asynchronous communication for messaging. When a message is sent, the sender's interface doesn't freeze; it continues to be responsive while the message is processed and delivered in the background.
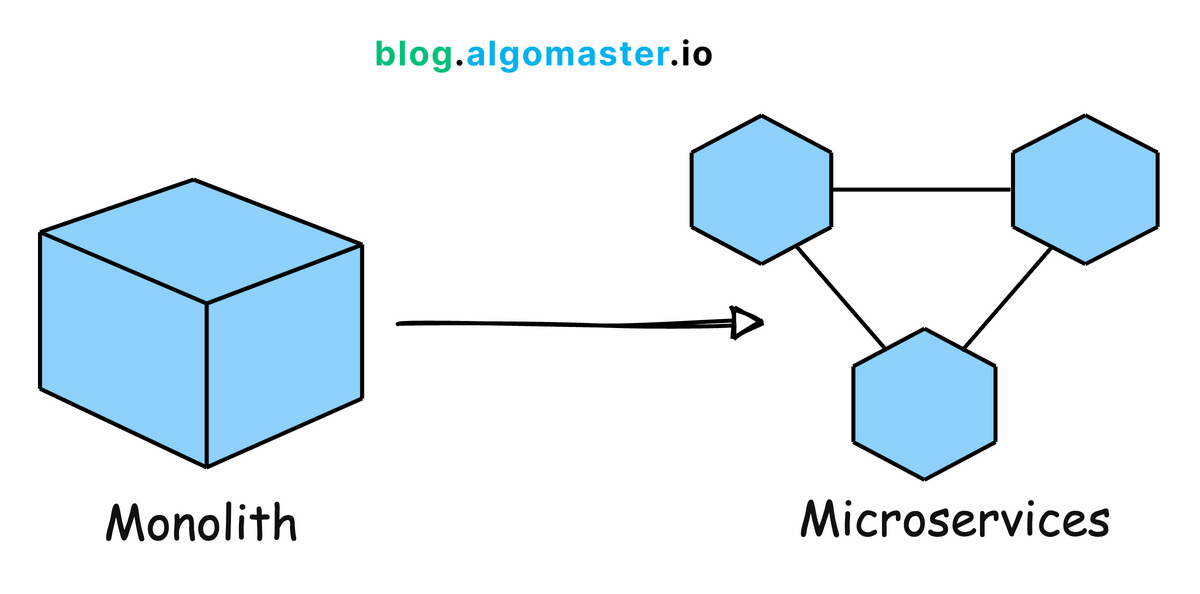
8. Microservices Architecture

Break down your application into smaller, independent services that can be scaled independently. This improves resilience and allows teams to work on specific components in parallel.
Example: Uber has evolved its architecture into microservices to handle different functions like billing, notifications, and ride matching independently, allowing for efficient scaling and rapid development.
9. Auto-Scaling

Automatically adjust the number of active servers based on the current load. This ensures that the system can handle spikes in traffic without manual intervention.
Example: AWS Auto Scaling monitors applications and automatically adjusts capacity to maintain steady, predictable performance at the lowest possible cost.
10. Multi-region Deployment
Deploy the application in multiple data centers or cloud regions to reduce latency and improve redundancy.
Example: Spotify uses multi-region deployments to ensure their music streaming service remains highly available and responsive to users all over the world, regardless of where they are located.
11. Service Mesh
Implement service mesh (e.g., Istio) to manage microservices traffic, security, and observability for better scalability and reliability.
A Service Mesh is a dedicated infrastructure layer that manages service-to-service communication in microservices architectures. It abstracts and automates functions like service discovery, load balancing, security (mutual TLS), traffic routing, and observability.
How it helps in scaling:
- Decouples Business Logic: Developers can focus on application logic while the service mesh handles networking concerns.
- Efficient Traffic Control: It balances and routes traffic dynamically, improving resource utilization.
- Resilience: Handles retries, timeouts, and circuit-breaking, enabling smoother horizontal scaling.
- Security: Manages authentication and encryption across services at scale without extra development.
Popular service meshes include Istio, Linkerd, and Consul.
Scalability Principles: The Golden Rules of System Design
Now that we’ve covered some essential scalability techniques, it’s time to explore the principles that guide their effective implementation. These principles can help you make informed decisions when designing and building scalable systems, ensuring that your solutions can adapt to ever-changing demands and requirements. Let’s dive into five key scalability principles that every system designer should know and master.
- Embrace Modularity: Modularity is the practice of breaking a system down into smaller, self-contained components. By designing modular systems, you can isolate and manage complexities more effectively, making it easier to scale individual components as needed. This approach also promotes better maintainability, as updates or bug fixes can be applied to specific modules without affecting the entire system. Keep modularity in mind when designing your system and strive to create components that can function independently and be easily integrated with others.
- Optimize for Latency: In a scalable system, minimizing latency is crucial to ensuring a responsive and satisfying user experience. To optimize for latency, consider employing caching, data compression, and efficient data retrieval techniques. Additionally, aim to minimize the number of round trips between clients and servers by batching requests and leveraging technologies like WebSockets for real-time communication. By prioritizing latency reduction, you’ll help guarantee that your system remains performant and user-friendly as it scales.
- Plan for Capacity: Capacity planning is a critical aspect of system design, as it helps you anticipate future resource requirements and make informed decisions about infrastructure and resource allocation. To plan effectively for capacity, regularly monitor your system’s performance, identify bottlenecks, and project future workloads based on historical data and trends. By staying proactive in your capacity planning efforts, you’ll be better prepared to accommodate growth and avoid performance degradation.
- Strive for Resilience: Scalable systems must be resilient, capable of recovering from failures and continuing to operate under adverse conditions. To build resilience into your system, consider implementing redundancy, fault tolerance, and automated failover mechanisms. Additionally, invest in monitoring and alerting tools to detect and respond to issues promptly. By designing for resilience, you’ll ensure that your system remains available and reliable, even as it grows in size and complexity.
- Prioritize Simplicity: A scalable system should be as simple as possible while still meeting its requirements. Complexity can hinder scalability, making it challenging to maintain, debug, and extend your system over time. To promote simplicity, aim to minimize dependencies between components, reduce code complexity, and adhere to well-established design patterns and best practices. By keeping your system design as straightforward as possible, you’ll make it easier to scale and evolve over time.
Mastering these scalability principles is key to becoming a proficient system designer. Keep these principles at the forefront of your system design efforts, and you’ll be well on your way to creating scalable, robust, and maintainable solutions that stand the test of time.
Best Practices for Designing Scalable Systems: Essential Tips for Success
When designing scalable systems, it’s crucial to adhere to a set of best practices that promote efficiency, maintainability, and growth. By following these guidelines, you’ll be better equipped to create solutions that can adapt to increasing demands and requirements. Let’s explore six essential best practices for designing scalable systems that every system designer should implement.
- Choose the Right Technologies: The foundation of any scalable system is the technology stack you choose to build upon. Selecting the right technologies, frameworks, and tools can make a significant difference in your system’s scalability and performance. When evaluating your options, consider factors such as community support, ease of use, and compatibility with your existing infrastructure. Opt for technologies that are proven to be performant and scalable, and that align with your team’s expertise and long-term goals.
- Leverage Horizontal Scaling: Horizontal scaling, or the practice of adding more machines to a system to handle increased load, is often more effective than vertical scaling (adding more resources to existing machines). By distributing workloads across multiple servers or instances, horizontal scaling can help your system scale more efficiently and handle traffic spikes more gracefully. Design your system with horizontal scaling in mind, and be prepared to add resources as needed to accommodate growth.
- Utilize Load Balancing: Load balancing is essential for distributing workloads evenly across your system’s resources, ensuring that no single component becomes a bottleneck. Implementing effective load balancing can help you maintain high availability and performance as your system scales. Consider using techniques such as round-robin, least connections, or session-based load balancing, depending on your system’s requirements and architecture.
- Monitor and Optimize Performance: Regularly monitoring your system’s performance is crucial for identifying bottlenecks and areas for optimization. Invest in monitoring tools that provide insights into key performance metrics, such as response times, error rates, and resource utilization. Use these insights to make data-driven decisions about optimizations, infrastructure upgrades, and other improvements that can enhance your system’s scalability.
- Implement Effective Caching: Caching is a powerful technique for reducing latency and improving performance in scalable systems. By storing frequently accessed data in memory, caching can significantly reduce the load on your system’s backend resources. Implement caching strategies such as in-memory caching, content delivery networks (CDNs), and browser caching to optimize your system’s performance and ensure a responsive user experience.
- Design for Security and Compliance: Scalable systems must be secure and compliant with relevant regulations and standards. As your system grows, so too does its potential attack surface and the complexity of managing security and compliance. Implement security best practices such as encryption, secure coding techniques, and vulnerability scanning to protect your system against threats. Additionally, ensure that your system adheres to applicable compliance requirements, such as GDPR or HIPAA.
How does Google Scale?
Google scales its systems through a combination of advanced strategies:
- Global Infrastructure: Google operates massive data centers globally, optimizing performance and ensuring low-latency access for users worldwide.
- Shard and Replicate Data: Google uses sharding to split large datasets and replication to store copies of data across different locations for reliability.
- Load Balancing: Traffic is distributed efficiently across thousands of servers using sophisticated load balancing mechanisms.
- Borg and Kubernetes: Google uses Borg (an internal system) and Kubernetes (open-source) for container orchestration, managing millions of containers at scale.
- Caching and CDNs: Google employs extensive caching and CDN strategies for quick data delivery.
These methods ensure Google can handle billions of queries and requests efficiently every day.
How does Google Scale?
Netflix scales its system using a variety of advanced techniques tailored for massive global distribution:
- Microservices Architecture: Netflix migrated from a monolithic architecture to microservices, enabling independent scaling of different services (e.g., video encoding, recommendation system).
- Global CDN (Open Connect): Netflix built its own content delivery network (CDN), Open Connect, to cache and deliver content closer to users, reducing latency.
- Cloud Infrastructure: Netflix leverages AWS for its cloud infrastructure, utilizing auto-scaling to adjust resources dynamically based on demand.
- Chaos Engineering: Tools like Chaos Monkey test the system’s resilience, preparing it for scaling and failure recovery.
These strategies allow Netflix to serve millions of users worldwide while maintaining high performance and reliability.
How does Microsoft Scale?
Microsoft scales its systems using several strategies:
- Global Cloud Infrastructure (Azure): Microsoft Azure powers services by providing on-demand scalability with data centers worldwide.
- Microservices and Containers: Microsoft utilizes microservices architecture for its cloud services and tools like Azure Kubernetes Service (AKS) to orchestrate containers at scale.
- Load Balancing & Auto-Scaling: Microsoft leverages auto-scaling and load balancing to adjust compute resources dynamically.
- Distributed Databases: Services like Azure Cosmos DB are designed for global scaling with multi-region replication.
- Edge Computing: Azure’s edge networks optimize content delivery close to users.
These technologies enable seamless scaling across Microsoft’s cloud, productivity, and enterprise platforms.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Comments
Post a Comment